
In Pandas, you can add a new column to an existing DataFrame using the DataFrame.insert() function, which updates the DataFrame in place. Alternatively, you can use DataFrame.assign() to insert a new column, but this method returns a new DataFrame with the added column.
Advertisements
In this article, I will cover examples of adding multiple columns, adding a constant value, deriving new columns from an existing column to the Pandas DataFrame.
Key Points –
- A new column can be created by assigning values directly to a new column name with
df['new_column'] = values. - The
assign()method adds columns and returns a modified copy of the DataFrame, leaving the original DataFrame unchanged unless reassigned. - Adding a column directly modifies the DataFrame in place, while using
assign()creates a new DataFrame. - Lambda functions within
assign()enable complex calculations or conditional logic to define values for the new column. - The
insert()method allows adding a new column at a specific position within the DataFrame, providing flexibility for organizing columns. - Using functions like
np.where()orapply(), you can populate a new column based on conditional values.
Quick Examples of Adding Column
If you are in a hurry, below are some quick examples of adding column to pandas DataFrame.
# Quick examples of add column to dataframe
# Add new column to the dataframe
tutors = ['William', 'Henry', 'Michael', 'John', 'Messi']
df2 = df.assign(TutorsAssigned=tutors)
# Add a multiple columns to the dataframe
MNCCompanies = ['TATA','HCL','Infosys','Google','Amazon']
df2 =df.assign(MNCComp = MNCCompanies,TutorsAssigned=tutors )
# Derive new Column from existing column
df = pd.DataFrame(technologies)
df2=df.assign(Discount_Percent=lambda x: x.Fee * x.Discount / 100)
# Add a constant or empty value to the DataFrame
df = pd.DataFrame(technologies)
df2=df.assign(A=None,B=0,C="")
# Add new column to the existing DataFrame
df = pd.DataFrame(technologies)
df["MNCCompanies"] = MNCCompanies
# Add new column at the specific position
df = pd.DataFrame(technologies)
df.insert(0,'Tutors', tutors )
# Add new column by mapping to the existing column
df = pd.DataFrame(technologies)
tutors = {"Spark":"William", "PySpark":"Henry", "Hadoop":"Michael","Python":"John", "pandas":"Messi"}
df['Tutors'] = df['Courses'].map(tutors)
print(df)
To run some examples of adding column to DataFrame, let’s create DataFrame using data from a dictionary.
# Create DataFrame
import pandas as pd
import numpy as np
technologies= {
'Courses':["Spark","PySpark","Hadoop","Python","Pandas"],
'Fee' :[22000,25000,23000,24000,26000],
'Discount':[1000,2300,1000,1200,2500]
}
df = pd.DataFrame(technologies)
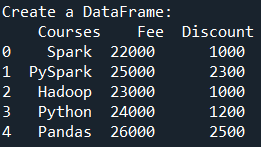
print("Create a DataFrame:\n", df)
Yields below output.
Add Column to DataFrame
DataFrame.assign() is used to add/append a column to the DataFrame, this method generates a new DataFrame incorporating the added column, while the original DataFrame remains unchanged.
Below is the syntax of the assign() method.
# Syntax of DataFrame.assign()
DataFrame.assign(**kwargs)
Now let’s add a column ‘TutorsAssigned” to the DataFrame. Using assign() we cannot modify the existing DataFrame inplace instead it returns a new DataFrame after adding a column. The below example adds a list of values as a new column to the DataFrame.
# Add new column to the DataFrame
tutors = ['William', 'Henry', 'Michael', 'John', 'Messi']
df2 = df.assign(TutorsAssigned=tutors)
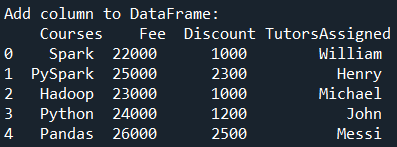
print("Add column to DataFrame:\n", df2)
Yields below output.
Add Multiple Columns to the DataFrame
You can add multiple columns to a Pandas DataFrame by using the assign() function.
# Add multiple columns to the DataFrame
MNCCompanies = ['TATA','HCL','Infosys','Google','Amazon']
df2 = df.assign(MNCComp = MNCCompanies,TutorsAssigned=tutors )
print("Add multiple columns to DataFrame:\n", df2)
Yields below output.
# Output:
# Add multiple columns to DataFrame:
Courses Fee Discount MNCComp TutorsAssigned
0 Spark 22000 1000 TATA William
1 PySpark 25000 2300 HCL Henry
2 Hadoop 23000 1000 Infosys Michael
3 Python 24000 1200 Google John
4 Pandas 26000 2500 Amazon Messi
Adding a Column From Existing
In real-time scenarios, there’s often a need to compute and add new columns to a dataset based on existing ones. The following demonstration calculates the Discount_Percent column based on Fee and Discount. In this instance, I’ll utilize a lambda function to generate a new column from the existing data.
# Derive New Column from Existing Column
df = pd.DataFrame(technologies)
df2 = df.assign(Discount_Percent=lambda x: x.Fee * x.Discount / 100)
print("Add column to DataFrame:\n", df2)
You can explore deriving multiple columns and appending them to a DataFrame within a single statement. This example yields the below output.
# Output:
# Add column to DataFrame:
Courses Fee Discount Discount_Percent
0 Spark 22000 1000 220000.0
1 PySpark 25000 2300 575000.0
2 Hadoop 23000 1000 230000.0
3 Python 24000 1200 288000.0
4 Pandas 26000 2500 650000.0
Add a Constant or Empty Column
The below example adds 3 new columns to the DataFrame, one column with all None values, a second column with 0 value, and the third column with an empty string value.
# Add a constant or empty value to the DataFrame.
df = pd.DataFrame(technologies)
df2=df.assign(A=None,B=0,C="")
print("Add column to DataFrame:\n", df2)
Yields below output.
# Output:
# Add column to DataFrame:
Courses Fee Discount A B C
0 Spark 22000 1000 None 0
1 PySpark 25000 2300 None 0
2 Hadoop 23000 1000 None 0
3 Python 24000 1200 None 0
4 Pandas 26000 2500 None 0
Append Column to Existing Pandas DataFrame
The above examples create a new DataFrame after adding new columns instead of appending a column to an existing DataFrame. The example explained in this section is used to append a new column to the existing DataFrame.
# Add New column to the existing DataFrame
df = pd.DataFrame(technologies)
df["MNCCompanies"] = MNCCompanies
print("Add column to DataFrame:\n", df2)
Yields below output.
# Output:
# Add column to DataFrame:
Courses Fee Discount MNCCompanies
0 Spark 22000 1000 TATA
1 PySpark 25000 2300 HCL
2 Hadoop 23000 1000 Infosys
3 Python 24000 1200 Google
4 Pandas 26000 2500 Amazon
You can also use this approach to add a new column by deriving from an existing column,
# Derive a new column from existing column
df2 = df['Discount_Percent'] = df['Fee'] * df['Discount'] / 100
print("Add column to DataFrame:\n", df2)
# Output:
# Add column to DataFrame:
# 0 220000.0
# 1 575000.0
# 2 230000.0
# 3 288000.0
# 4 650000.0
dtype: float64
Add Column to Specific Position of DataFrame
The DataFrame.insert() method offers the flexibility to add columns at any position within an existing DataFrame. While many examples often showcase appending columns at the end of the DataFrame, this method allows for insertion at the beginning, in the middle, or at any specific column index of the DataFrame.
# Add new column at the specific position
# Add new column to the DataFrame
tutors = ['William', 'Henry', 'Michael', 'John', 'Messi']
df.insert(0,'Tutors', tutors )
print("Add column to DataFrame:\n", df)
# Insert 'Tutors' column at the specified position
# Add new column to the DataFrame
position = 0
df.insert(position, 'Tutors', tutors)
print("Add column to DataFrame:\n", df)
Yields below output.
# Output:
# Add column to DataFrame:
Tutors Courses Fee Discount
0 William Spark 22000 1000
1 Henry PySpark 25000 2300
2 Michael Hadoop 23000 1000
3 John Python 24000 1200
4 Messi Pandas 26000 2500
Add a Column From Dictionary Mapping
If you want to add a column with specific values for each row based on an existing value, you can do this using a Dictionary. Here, The values from the dictionary will be added as Tutors column in df, by matching the key value with the column 'Courses'.
# Add new column by mapping to the existing column
df = pd.DataFrame(technologies)
tutors = {"Spark":"William", "PySpark":"Henry", "Hadoop":"Michael","Python":"John", "pandas":"Messi"}
df['Tutors'] = df['Courses'].map(tutors)
print("Add column to DataFrame:\n", df)
Note that it is unable to map pandas as the key in the dictionary is not exactly matched with the value in the Courses column (case sensitive). This example yields the below output.
# Output:
# Add column to DataFrame:
Courses Fee Discount Tutors
0 Spark 22000 1000 William
1 PySpark 25000 2300 Henry
2 Hadoop 23000 1000 Michael
3 Python 24000 1200 John
4 Pandas 26000 2500 NaN
Using loc[] Add Column
Using pandas loc[] you can access rows and columns by labels or names however, you can also use this for adding a new column to pandas DataFrame. This loc[] property uses the first argument as rows and the second argument for columns hence, I will use the second argument to add a new column.
# Assign the column to the DataFrame
df = pd.DataFrame(technologies)
tutors = ['William', 'Henry', 'Michael', 'John', 'Messi']
df.loc[:, 'Tutors'] = tutors
print("Add column to DataFrame:\n", df)
Yields the same output as above.