
What is Statistics and Why is It Needed for Data Science?
The necessary foundation for machine learning algorithms involves learning maths and statistics for Data Science. Data scientists must practice statistics as it is the study of collection, analysis, interpretation, presentation, and organization of data as the Wikipedia states it. There is a strong relationship between Data Science and Statistics. Data scientists need Statistics for data science projects as it provides tools and methods to find structures and give more profound insights into data.
Some of the popular terminology in the field of data science is:
- Population: Set of sources from where data is collected.
- Sample: A subset of the population.
- Variable: Any number, characteristics, or quantity that can be measured or counted and also referred to as a data item.
- Statistical Parameter: Also called a statistical model or population parameter. It is the quantity that indexes a family of probability distributions — for instance, the mean, median of a population.
The primary role that Statistics offers in Data Science is:
- Researchers leverage data resources to extract knowledge and obtain better answers by statistically framing questions.
- Statistical inference states that there exists a component of randomness in data that enables the researchers to formulate questions in the underlying processes and to quantify the uncertainty in their answers.
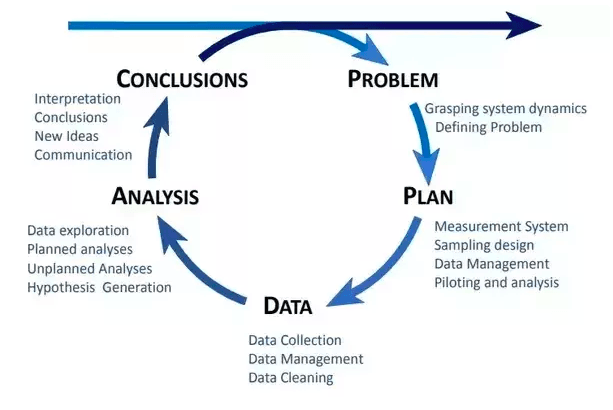
The Statistical Inquiry Cycle
- A statistical framework permits researchers to distinguish between causation and correlation, thereby identifying interventions that caused changes in the outcomes.
- The framework allows the scientists to establish methods for estimation and prediction hence quantifying the degree of certainty, and this is done using an algorithm that exhibits reproducible and predictable behavior.
- Statistical methods aim to focus attention on findings that can be reproduced by other researchers with different data resources.
- Statistical methods allow researchers to accumulate knowledge.
Analysis using Statistics
Below are the types in which analysis of an event:
- Quantitative Analysis: Also termed as Statistical Analysis is the science of collecting and interpreting data with graphs and numbers to identify patterns and trends.
- Qualitative Analysis: Also known as Non-Statistical Analysis gives general information and uses text, sound, and various other forms of media to do so.
For instance, if we buy a movie ticket, it is sold as Silver, Gold, or Platinum tickets, this is an example of a Qualitative analysis. But if the theatre sells 200 regular tickets per week, it is Quantitative analysis because we have a number representing tickets sold per week.
Categories in Statistics
Learning statistics involves three categories:
1. Descriptive Statistics
Descriptive statistics helps analysts to describe, show, or summarize data in a meaningful way such that, for example, we can derive patterns from data. However, descriptive statistics doesn’t allow us to make conclusions beyond the data that has been analyzed or reached a conclusion regarding any hypothesis, already made. The need for descriptive analysis is essential because if we present the raw data, it would be hard to visualize what data showed before. Therefore, descriptive statistics enable us to present the data in a more meaningful way hence, allowing a more straightforward interpretation of data. There generally exist two types of statistics that describe data:
- Measures of Central Tendency: Describes the central position of a frequency distribution for a group of data. The frequency distribution is the distribution and pattern marks scored from the lowest to the highest.
- Measures of Spread: Summarizes a group of data by describing how the scores spread. For example, the mean score of 100 students being 65 doesn’t imply that all students have scored 65 marks; instead, their scores be spread out. Measures of spread help to summarize how spread out are the scores. Several statistics are available, including the range, quartiles, absolute deviation, variance, and standard deviation used to describe spread,
2. Inferential Statistics
As we know, descriptive statistics provide information about the next group of data. For example, calculating the mean and standard deviation of the exam marks for the 100 students and providing valuable information about this group of 100 students. A population can be small or large, provided it includes all the data interests the user. For instance, if you were only interested in the exam marks of 100 students, those 100 students would represent the population. Descriptive statistics are applied to the properties of populations and populations, such as the mean or standard deviation, called parameters as they represent the whole population.
Often, however, the user does not have access to the whole population you are interested in investigating, but instead only a limited number of data. For instance, you might be interested in the exam marks of all students in the US, which is not feasible to measure all exam marks of all students in the whole of the US. Therefore, a user has to measure a smaller sample of students (e.g., 100 students), which are used to represent the larger population of all US students. Properties of samples, such as the standard deviation or mean, are statistics but not parameters.
Inferential statistics is a technique that allows the user to utilize these samples to make generalizations about populations from which samples are drawn. Hence, it is vital that the sample accurately represents the population termed as sampling. Inferential statistics arises due to the fact that sampling naturally incurs error, and thus a sample is not expected to represent the population correctly. The methods of inferential statistics are (1) testing of statistical hypotheses and (2) the estimation of the parameter(s).
3. Predictive Modelling
Predictive modeling is the process that uses data mining and probability to forecast outcomes. Each model is made up of several predictors, which are variables that are likely to influence future results. Once data has been collected for relevant predictors, the formulation of a statistical model takes place. The model may employ a simple linear equation, or it may be a complex neural network, mapped out by sophisticated software. As additional data becomes available, the statistical analysis model is validated or revised.
Applications of Predictive modeling:
- Meteorology and weather forecasting
- Online advertising and marketing
- Bayesian spam filters
- Fraud detection
- Customer relationship management
- Capacity planning
- Change management
- Disaster recovery
- Engineering
- Physical and digital security management
- City planning
Concepts of Data Science, a Data Scientist, must Know
1. Core Statistical Features
Statistical features are often the first stats technique that data scientists apply when exploring a dataset and include things like bias, mean, variance, percentiles, and median, and many others. The statistical features are most used concept in Data science as it is relatively easy to understand and implement in code.
The graph illustrated below further explains this:
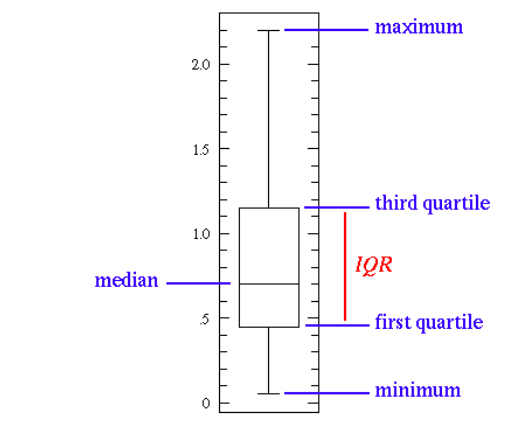
A basic box plot
The line in the middle represents the median value of data. Scientists prefer median over means as it is more robust to outlier values. The first quartile is essentially the 25% percentile, i.e., 25% of the points are below that value. Similarly, the third quartile is the 75th percentile, i.e., 75% of the points are below that value. The max and min values represent the lower and upper ends of the data, respectively.
What the box plot can illustrate all we can do with statistical features:
A short box plot implies that much of the data points are similar, as there are many similar values in a small range.
A tall box plot implies that much of the data points are quite different since it uses the values over a wide range.
If the median value closer to the bottom tells us that most of the data has lower values, whereas, if the median is closer to the top, then it tells us that most of the data has higher values. In short, if the median does not lie in the middle of the box, it indicates skewed data.
“Whiskers are long” is a phrase that means the data has high standard deviation and variance, i.e., the values are spread out are highly varying. If data is highly varying in one direction, then the whiskers exist only on that side of the box.
2. Probability
As per Wikipedia Probability is the measure quantifying the likelihood that events occur. Probability is commonly quantified in the range 0 to 1, where 0 means we are confident this will not occur, and 1 indicates the certainty of its occurrence. A probability distribution is a function that represents the probabilities of all possible values in the experiment.
Discussed below are the standard probability distributions:
3. Uniform Distribution

Uniform Distribution
A uniform distribution has a single value that only occurs in a particular range, while anything outside the range is considered 0. It is an “on or off” distribution since we can take it as an indication of a categorical value. Categorical values can have multiple values apart from 0, but scientists can still visualize it in the same as was a piecewise function of multiple uniform distributions.
4. Normal Distribution

Normal Distribution
Also referred to as Gaussian distribution, it is defined explicitly by its means and standard deviation. The standard deviation controls the spread, and the mean value shifts the distribution spatially. The main difference from other probability distributions is that the standard deviation is the same in all directions. So, the Gaussian distribution tells the average value of the dataset and the spread of the data i.e., it spread over a wide range of it is high concentration around a few values.
5. Poisson Distribution
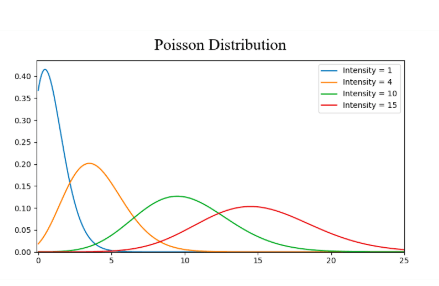
The distribution is similar to Normal distribution except that it has added a factor of skewness. Poisson distribution has relatively uniform spread in all directions, just like the Normal with a low value for the skewness. But when the skewness value is high in magnitude, then the spread of our data differs in a different direction; it is very spread in one direction and highly concentrated in another direction.
6. Dimensionality Reduction
In the classification problem in machine learning, there are too many features based on which we do final classification. With a higher number of features, it gets harder to visualize the training set and then to work on it. Most of the features sometimes are correlated or redundant, where dimensionality reduction algorithms come into play. Dimensional reduction is the process of reducing the number of random variables under consideration by obtaining a set of principal variables.
Components of Dimensionality reduction:
- Feature Selection: Tries to find a subset of the original set of variables, or features, to get a smaller model that is used to model the problem. Any of the three ways does feature selection:
- Filter
- Wrapper
- Embedded
- Feature Extraction: Reduce the data in a high dimensional space to a lower-dimensional space that means a space with a lower number of dimensions.
Feature pruning is another way to make Dimensionality reduction, which involves removing features that prove to be unimportant for analysis. For instance, after exploring data set 7 features out of 10 features might have a high correlation with the output, but the other 3 have a very low correlation. So, those three features probably aren’t worth the compute, and we can remove them from the analysis without tampering the output.
PCA is the most common dimensionality reduction that essentially creates vector representations of feature, thereby showing their importance for the output i.e., correlation.
7. Bayesian Thinking and Statistics
Bayesian statistics is a mathematical procedure that applies probabilities to statistical problems. It provides people with tools to update their beliefs in the evidence of the new data. A person must have skills in linear algebra and probability and statistics, as they are the prerequisites to know before Bayesian statistics.
Concepts used in Bayesian thinking:
Conditional Probability
Probability of an event A given B equals the probability of B and A happening together divided by the probability of B – defines conditional probability.
Bayes Theorem

Bayes’ Theorem
The probability P(H) is the frequency analysis; given prior data, what is the probability of the event occurring. The P(E|H) in the equation is the likelihood and is essentially the probability that our evidence is correct, where the information provided from frequency analysis. The P(E) is the probability that the actual evidence is valid.
Machine Learning
Learning and exploring machine learning models helps to step into statistics for data science. Several models are chosen to define several key concepts.
- Linear Regression: Finds the relationship between the target and one or more predictors. It is of two types: simple and multiple.
- Naive Bayes Classifier: Collection of algorithms based on Bayes’ Theorem sharing a universal principle i.e., every pair of features classified is independent of each other.
- Multi-Armed Bandits: A multi-armed bandit problem is an example of reinforcement learning where we a slot machine with ‘n’ arms called bandits, given with each arm having its rigged probability distribution of success. A stochastic reward given by pulling any one of the arms; the reward is either R= +1 for success or R=0 for failure. The objective is to pull the arms one-by-one in sequence such that the total score collected gets maximized.