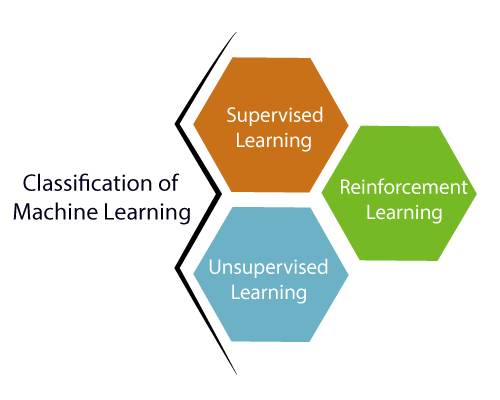
A machine learns from a trained data set to create a model. Whenever there is a new input to the algorithm, it predicts on the basis of the model. The evaluation is made in terms of accuracy, and the algorithm is deployed only if the accuracy is accepted by the algorithm of machine learning, else the model is trained repeatedly with a large data set. The machine learning algorithm can be broadly classified into 3 main categories;
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Supervised Learning
Supervised learning is the one done under the supervision of a teacher or a supervisor. Basically, the model is trained over a labeled dataset. A labeled database is one which contains both inputs as well as the output parameters. Here the trained dataset act a teacher, and its primary role is to train the model. The prediction is made once the model is built. It works in the same manner as the student learns under the supervision of the teacher.
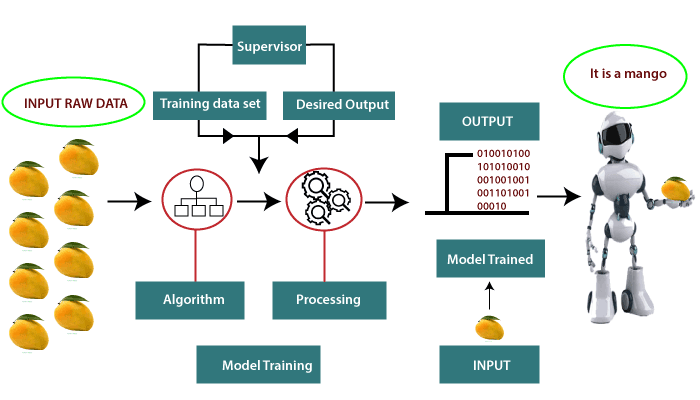
In the supervised learning, the input, as well as the output, is provided to the model aiming to find a mapping function that maps an input variable (P) to the output variable (Q). The supervised learning is used for fraud detection, risk assessment, spam filtering, etc.
Types of Supervised Learning:-
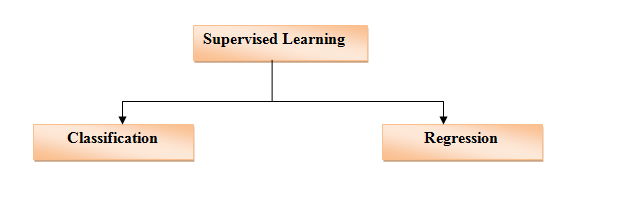
Classification: – Classification based algorithms are used whenever there is some certain (discrete value) output variable, i.e., either Red or Blue, Yes-No, Male-Female, 0 or 1, etc. The real-world example would be spam filter.
Random Forest
- Naïve Bayes
- Decision Trees
- Logistic regression
- Support Vector Machine(SVM)
Regression: – The regression-based classification method is used for the prediction of continuous values, especially in the case when the input and output variables are related to each other. It focuses on calculating a value closer to the output value. It is employed in weather forecasting etc.
Types of Regression-based algorithm:: –
- Linear Regression
- Regression Trees
Unsupervised Learning: –
It is a kind of learning in which the output target is not given to the model while performing the training. It only has the input variables. The model has to lean itself. The trained data that is fed to the system can be unlabeled as well as unstructured in nature.
The unstructured data is the one where the noise or some irrelevant information is present, whereas in case of unlabeled data it does not contain any target value other than the input data and is easy to collect as compared to labeled one in the supervised learning.
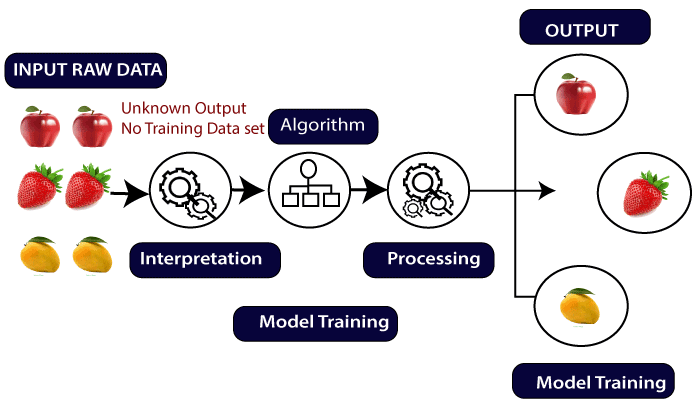
Types of Unsupervised Learning:-
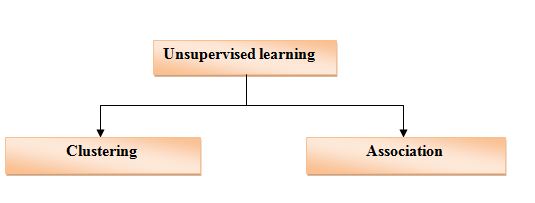
Clustering is a technique in which the model groups the data based on different patterns, whereas in the case of association; it is a rule-based technique. It is used to find out the relevant relationship between the parameters of a dataset.
Types of Unsupervised based learning algorithms: –
- DBSCAN
- Hierarchical Clustering
- K-means clustering
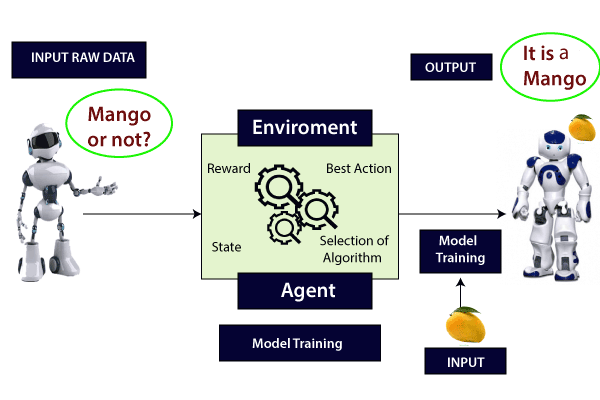
Reinforcement based Learning: –
In this type of learning, the agent connects with the environment and searches for the best outcome. It is a hit and trial method. Based on the result, the author may be either rewarded or penalized for every wrong and correct answer. The more the positive rewards points gained, the more the model can train itself. And the prediction is made after getting trained entirely.