
The reflex agents are known as the simplest agents because they directly map states into actions. Unfortunately, these agents fail to operate in an environment where the mapping is too large to store and learn. Goal-based agent, on the other hand, considers future actions and the desired outcomes.
Here, we will discuss one type of goal-based agent known as a problem-solving agent, which uses atomic representation with no internal states visible to the problem-solving algorithms.
Problem-solving agent
The problem-solving agent perfoms precisely by defining problems and its several solutions.
According to psychology, “a problem-solving refers to a state where we wish to reach to a definite goal from a present state or condition.”
According to computer science, a problem-solving is a part of artificial intelligence which encompasses a number of techniques such as algorithms, heuristics to solve a problem.
Therefore, a problem-solving agent is a goal-driven agent and focuses on satisfying the goal.
Steps performed by Problem-solving agent
- Goal Formulation: It is the first and simplest step in problem-solving. It organizes the steps/sequence required to formulate one goal out of multiple goals as well as actions to achieve that goal. Goal formulation is based on the current situation and the agent’s performance measure (discussed below).
- Problem Formulation: It is the most important step of problem-solving which decides what actions should be taken to achieve the formulated goal. There are following five components involved in problem formulation:
- Initial State: It is the starting state or initial step of the agent towards its goal.
- Actions: It is the description of the possible actions available to the agent.
- Transition Model: It describes what each action does.
- Goal Test: It determines if the given state is a goal state.
- Path cost: It assigns a numeric cost to each path that follows the goal. The problem-solving agent selects a cost function, which reflects its performance measure. Remember, an optimal solution has the lowest path cost among all the solutions.
Note: Initial state, actions, and transition model together define the state-space of the problem implicitly. State-space of a problem is a set of all states which can be reached from the initial state followed by any sequence of actions. The state-space forms a directed map or graph where nodes are the states, links between the nodes are actions, and the path is a sequence of states connected by the sequence of actions.
- Search: It identifies all the best possible sequence of actions to reach the goal state from the current state. It takes a problem as an input and returns solution as its output.
- Solution: It finds the best algorithm out of various algorithms, which may be proven as the best optimal solution.
- Execution: It executes the best optimal solution from the searching algorithms to reach the goal state from the current state.
Example Problems
Basically, there are two types of problem approaches:
- Toy Problem: It is a concise and exact description of the problem which is used by the researchers to compare the performance of algorithms.
- Real-world Problem: It is real-world based problems which require solutions. Unlike a toy problem, it does not depend on descriptions, but we can have a general formulation of the problem.
Some Toy Problems
- 8 Puzzle Problem: Here, we have a 3×3 matrix with movable tiles numbered from 1 to 8 with a blank space. The tile adjacent to the blank space can slide into that space. The objective is to reach a specified goal state similar to the goal state, as shown in the below figure.
- In the figure, our task is to convert the current state into goal state by sliding digits into the blank space.
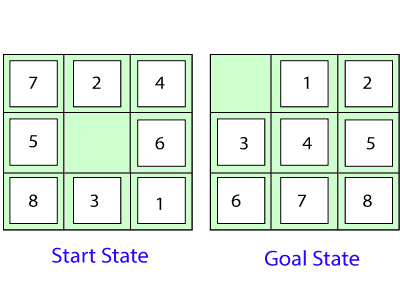
In the above figure, our task is to convert the current(Start) state into goal state by sliding digits into the blank space.
The problem formulation is as follows:
- States: It describes the location of each numbered tiles and the blank tile.
- Initial State: We can start from any state as the initial state.
- Actions: Here, actions of the blank space is defined, i.e., either left, right, up or down
- Transition Model: It returns the resulting state as per the given state and actions.
- Goal test: It identifies whether we have reached the correct goal-state.
- Path cost: The path cost is the number of steps in the path where the cost of each step is 1.
Note: The 8-puzzle problem is a type of sliding-block problem which is used for testing new search algorithms in artificial intelligence.
- 8-queens problem: The aim of this problem is to place eight queens on a chessboard in an order where no queen may attack another. A queen can attack other queens either diagonally or in same row and column.
From the following figure, we can understand the problem as well as its correct solution.

It is noticed from the above figure that each queen is set into the chessboard in a position where no other queen is placed diagonally, in same row or column. Therefore, it is one right approach to the 8-queens problem.
For this problem, there are two main kinds of formulation:
- Incremental formulation: It starts from an empty state where the operator augments a queen at each step.
Following steps are involved in this formulation:
- States: Arrangement of any 0 to 8 queens on the chessboard.
- Initial State: An empty chessboard
- Actions: Add a queen to any empty box.
- Transition model: Returns the chessboard with the queen added in a box.
- Goal test: Checks whether 8-queens are placed on the chessboard without any attack.
- Path cost: There is no need for path cost because only final states are counted.
In this formulation, there is approximately 1.8 x 1014 possible sequence to investigate.
- Complete-state formulation: It starts with all the 8-queens on the chessboard and moves them around, saving from the attacks.
Following steps are involved in this formulation
- States: Arrangement of all the 8 queens one per column with no queen attacking the other queen.
- Actions: Move the queen at the location where it is safe from the attacks.
This formulation is better than the incremental formulation as it reduces the state space from 1.8 x 1014 to 2057, and it is easy to find the solutions.
Some Real-world problems
- Traveling salesperson problem(TSP): It is a touring problem where the salesman can visit each city only once. The objective is to find the shortest tour and sell-out the stuff in each city.
- VLSI Layout problem: In this problem, millions of components and connections are positioned on a chip in order to minimize the area, circuit-delays, stray-capacitances, and maximizing the manufacturing yield.
The layout problem is split into two parts:
- Cell layout: Here, the primitive components of the circuit are grouped into cells, each performing its specific function. Each cell has a fixed shape and size. The task is to place the cells on the chip without overlapping each other.
- Channel routing: It finds a specific route for each wire through the gaps between the cells.
- Protein Design: The objective is to find a sequence of amino acids which will fold into 3D protein having a property to cure some disease.
Searching for solutions
We have seen many problems. Now, there is a need to search for solutions to solve them.
In this section, we will understand how searching can be used by the agent to solve a problem.
For solving different kinds of problem, an agent makes use of different strategies to reach the goal by searching the best possible algorithms. This process of searching is known as search strategy.
Measuring problem-solving performance
Before discussing different search strategies, the performance measure of an algorithm should be measured. Consequently, there are four ways to measure the performance of an algorithm:
Completeness: It measures if the algorithm guarantees to find a solution (if any solution exist).
Optimality: It measures if the strategy searches for an optimal solution.
Time Complexity: The time taken by the algorithm to find a solution.
Space Complexity: Amount of memory required to perform a search.
The complexity of an algorithm depends on branching factor or maximum number of successors, depth of the shallowest goal node (i.e., number of steps from root to the path) and the maximum length of any path in a state space.
Search Strategies
There are two types of strategies that describe a solution for a given problem:
Uninformed Search (Blind Search)
This type of search strategy does not have any additional information about the states except the information provided in the problem definition. They can only generate the successors and distinguish a goal state from a non-goal state. These type of search does not maintain any internal state, that’s why it is also known as Blind search.
There are following types of uninformed searches:
- Breadth-first search
- Uniform cost search
- Depth-first search
- Depth-limited search
- Iterative deepening search
- Bidirectional search
Informed Search (Heuristic Search)
This type of search strategy contains some additional information about the states beyond the problem definition. This search uses problem-specific knowledge to find more efficient solutions. This search maintains some sort of internal states via heuristic functions (which provides hints), so it is also called heuristic search.
There are following types of informed searches:
- Best first search (Greedy search)
- A* search