
Measures of central tendency help you find the middle, or the average, of a data set. The 3 most common measures of central tendency are the mode, median, and mean.
- Mode: the most frequent value.
- Median: the middle number in an ordered data set.
- Mean: the sum of all values divided by the total number of values.
A data set is a distribution of n number of scores or values.
When we learn Data Science as beginners we came across a very common term known as Central Tendency Measure with 3 M’s, Mean, Median and Mode. One should understand what do these terms mean and when they are given priority while analyzing any data set and concluding a decision depending upon the types of data.
Types of Data
The data available for analysis always have two main categories, Quantitative and Qualitative. Quantitative data has numerical values such as time, speed, etc. whereas Qualitative data have non-numerical values such as color, yes or no, etc. There are two types of Quantitative data, Discrete and Continuous. The Discrete data has values that can not be broken down into fractions such as numbers on dice, number of students in a class, etc. while the Continuous data can be available in fractional values such as the height of a person, distance, etc.
The data can be further classified into Nominal, Ordinal, Interval, and Ratio data. Nominal data is categorical data such as gender, religion, etc. Ordinal data is a measure of rank or order such as exam grades, position in the company, etc. Interval data is a measure of equality and interval such as 30 oC is hotter than 15 oC, water is in liquid form when the temperature is in between 0 oC and 100 oC. etc. When in addition to setting up inequalities we can also form quotients such data is known as Ratio data, such as the ratio of height, weight, etc.
The measure of Central Tendency
We should first understand the term Central Tendency. Data tend to accumulate around the average value of the total data under consideration. Measures of central tendency will help us to find the middle, or the average, of a data set. If most of the data is centrally located and there is a very small spread it will form an asymmetric bell curve. In such conditions values of mean, median and mode are equal.
Mean: It is the average of values. Consider 3 temperature values 30 oC, 40 oC and 50 oC, then the mean is (30+40+50)/3=40 oC.
Median: It is the centrally located value of the data set sorted in ascending order. Consider 11 (ODD) values 1,2,3,7,8,3,2,5,4,15,16. We first sort the values in ascending order 1,2,2,3,3,4,5,7,8,15,16 then the median is 4 which is located at the 6th number and will have 5 numbers on either side.


If the data set is having an even number of values then the median can be found by taking the average of the two middle values. Consider 10 (EVEN) values 1,2,3,7,8,3,2,5,4,15. We first sort the values in ascending order 1,2,2,3,3,4,5,7,8,15 then the median is (3+4)/2=3.5 which is the average of the two middle values i.e. the values which are located at the 5th and 6th number in the sequence and will have 4 numbers on either side.


Mode: It is the most frequent value in the data set. We can easily get the mode by counting the frequency of occurrence. Consider a data set with the values 1,5,5,6,8,2,6,6. In this data set, we can observe the following,
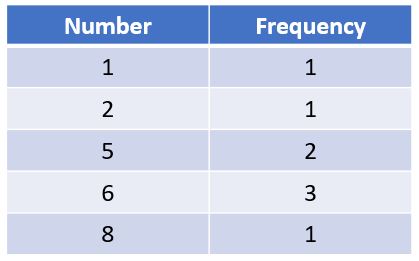
The value 6 occurs the most hence the mode of the data set is 6.
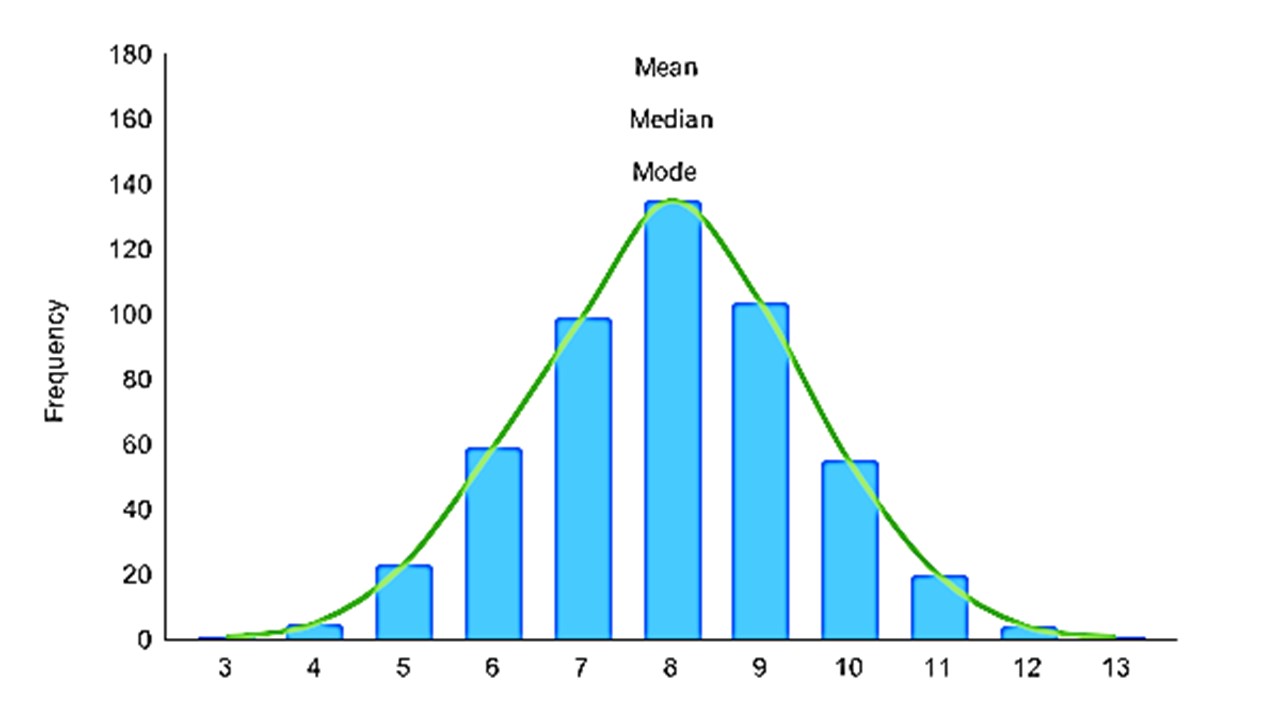
We often test our data by plotting the distribution curve, if most of the values are centrally located and very few values are off from the center then we say that the data is having a normal distribution. At that time the values of mean, median, and mode are almost equal.
However, when our data is skewed, for example, as with the right-skewed data set below:
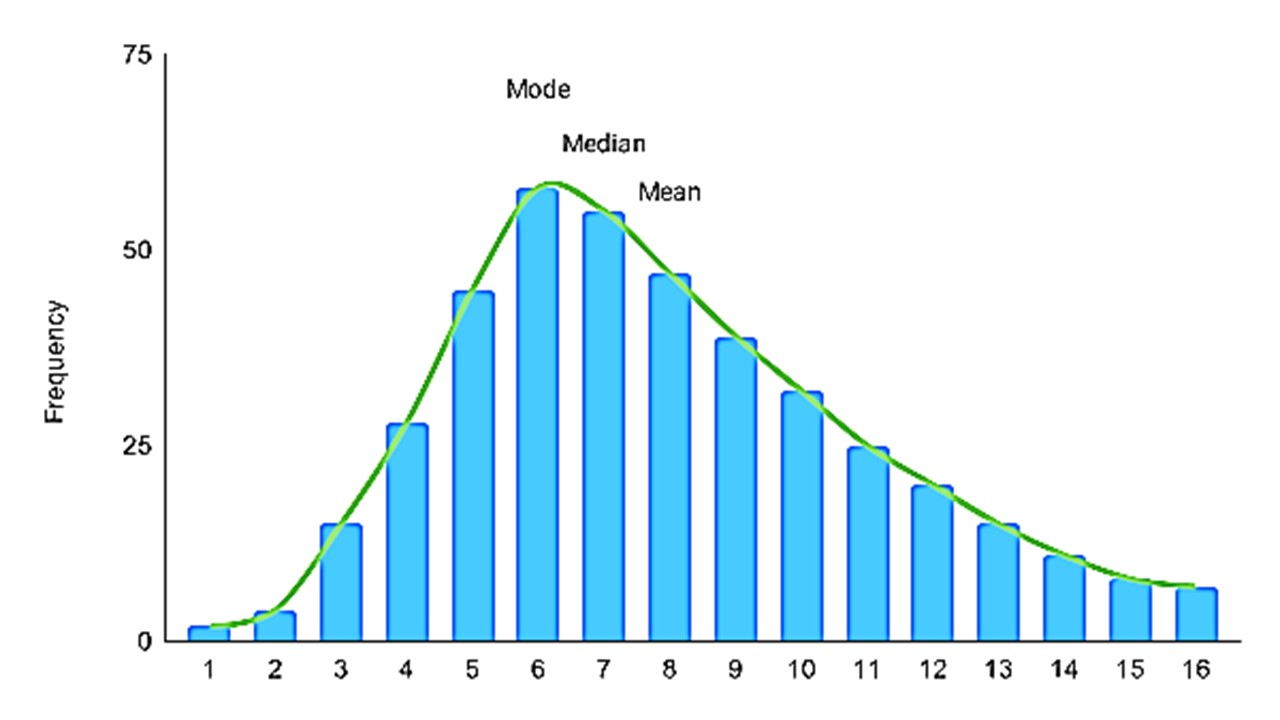
We can say that the mean is being dragged in the direction of the skew. In this skewed distribution, mode < median < mean. The more skewed the distribution, the greater the difference between the median and mean, here we consider median for the conclusion. The best example of the right-skewed distribution is salaries of employees, where higher-earners provide a false representation of the typical income if expressed as mean salaries and not the median salaries.
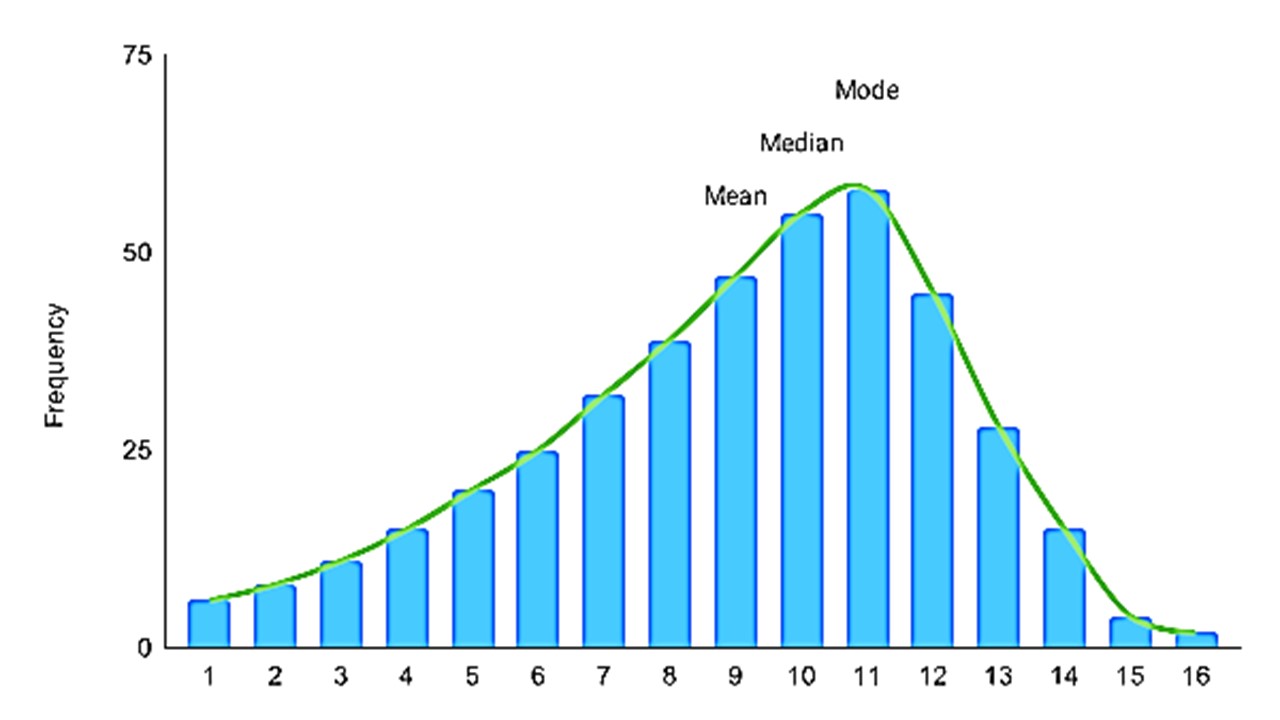
For left-skewed distribution mean < median < mode. In such a case also, we emphasize the median value of the distribution.
Example :
To understand this let us consider an example. An OTT platform company has conducted a survey in a particular region based on the watch time, language of streaming, and age of the viewer. for our understanding, we have taken a sample of 10 people.
df=pd.read_csv("viewer.csv")
df
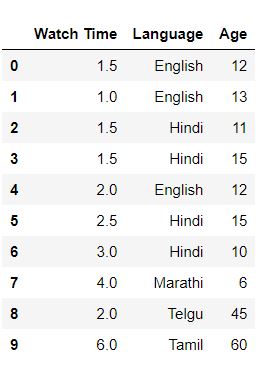
df["Watch Time"].mean() 2.5 df["Watch Time"].mode() 0 1.5 dtype: float64 df["Watch Time"].median() 2.0
If we observe the values then we can conclude the value of Mean Watch Time is 2.5 hours and which appears reasonably correct. For Age of viewer following results can be obtained,
df["Age"].median() 12.5 df["Age"].mean() 19.9 df["Age"].mode() 0 12 1 15 dtype: int64
The value of mean Age is looked somewhat away from the actual data. Most of the viewers are in the range of 10 to 15 while the value of mean comes 19.9. This is because the outliers present in the data set. We can easily find the outliers using a boxplot.
sns.boxplot(df['Age'], orient='vertical')
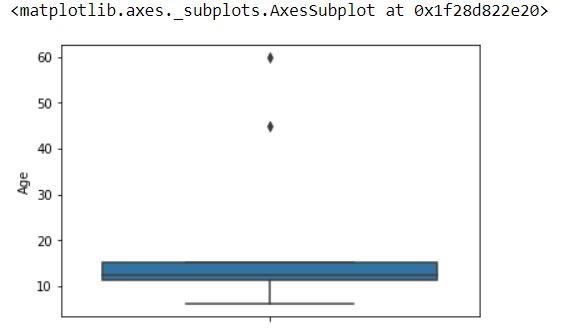
If we observe the value of Median Age then the result looks correct. The value of mean is very sensitive to outliers.
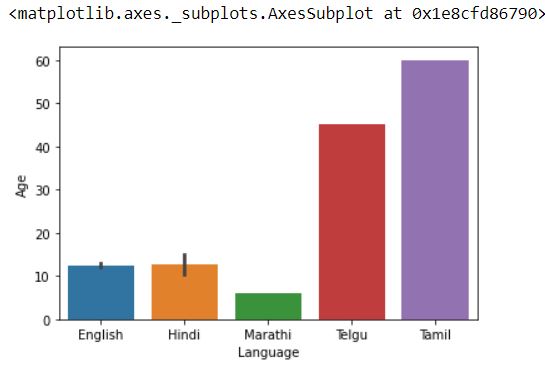
Now for the most popular language, we can not calculate the mean and median since this is nominal data.
sns.barplot(x="Language",y="Age",data=df)
sns.barplot(x="Language",y="Watch Time",data=df)
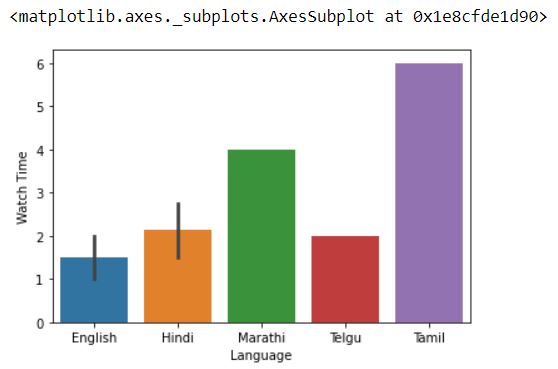
If we observe the graph then it is seen that the Tamil bar is largest for Language vs Age and Language vs Watch Time graph. But this will mislead the result because there is only one person who watches the shows in Tamil.
df["Language"].value_counts() Hindi 4 English 3 Tamil 1 Telgu 1 Marathi 1 Name: Language, dtype: int64 df["Language"].mode() 0 Hindi dtype: object
From the above result, it is concluded that the most popular language is Hindi. This is observed when we find the mode of the data set.
Hence from the above observation, it is concluded that in the sample survey average age of viewers is 12.5 years who watch for 2.5 hours daily a show in the Hindi language.
We can say there is no best central tendency measure method because the result is always based on the types of data. For ordinal, interval, and ratio data (if it is skewed) we can prefer median. For Nominal data, the model is preferred and for interval and ratio data (if it is not skewed) mean is preferred.