
What is an Agent?
An agent can be viewed as anything that perceives its environment through sensors and acts upon that environment through actuators.
For example, human being perceives their surroundings through their sensory organs known as sensors and take actions using their hands, legs, etc., known as actuators.
Diagrammatic Representation of an Agent
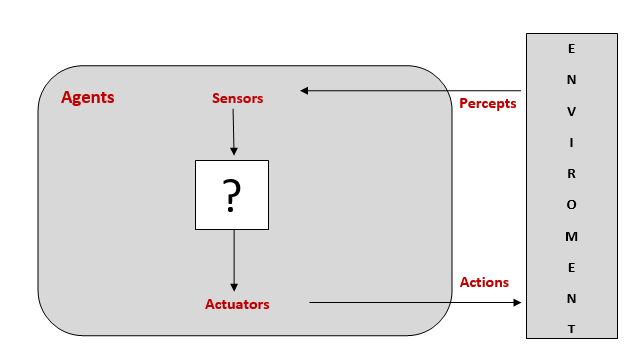
Agents interact with the environment through sensors and actuators
Intelligent Agent
An intelligent agent is a goal-directed agent. It perceives its environment through its sensors using the observations and built-in knowledge, acts upon the environment through its actuators.
Rational Agent
A rational agent is an agent which takes the right action for every perception. By doing so, it maximizes the performance measure, which makes an agent be the most successful.
Note: There is a slight difference between a rational agent and an intelligent agent.
Omniscient Agent
An omniscient agent is an agent which knows the actual outcome of its action in advance. However, such agents are impossible in the real world.
Note: Rational agents are different from Omniscient agents because a rational agent tries to get the best possible outcome with the current perception, which leads to imperfection. A chess AI can be a good example of a rational agent because, with the current action, it is not possible to foresee every possible outcome whereas a tic-tac-toe AI is omniscient as it always knows the outcome in advance.
Software Agents
It is a software program which works in a dynamic environment. These agents are also known as Softbots because all body parts of software agents are software only. For example, video games, flight simulator, etc.
Behavior of an Agent
Mathematically, an agent behavior can be described by an:
- Agent Function: It is the mapping of a given percept sequence to an action. It is an abstract mathematical explanation.
- Agent Program: It is the practical and physical implementation of the agent function.
For example, an automatic hand-dryer detects signals (hands) through its sensors. When we bring hands nearby the dryer, it turns on the heating circuit and blows air. When the signal detection disappears, it breaks the heating circuit and stops blowing air.
Rationality of an agent
It is expected from an intelligent agent to act in a way that maximizes its performance measure. Therefore, the rationality of an agent depends on four things:
- The performance measure which defines the criterion of success.
- The agent’s built-in knowledge about the environment.
- The actions that the agent can perform.
- The agent’s percept sequence until now.
For example: score in exams depends on the question paper as well as our knowledge.
Note: Rationality maximizes the expected performance, while perfection maximizes the actual performance which leads to omniscience.
Task Environment
A task environment is a problem to which a rational agent is designed as a solution. Consequently, in 2003, Russell and Norvig introduced several ways to classify task environments. However, before classifying the environments, we should be aware of the following terms:
- Performance Measure: It specifies the agent’s sequence of steps taken to achieve its target by measuring different factors.
- Environment: It specifies the interaction of the agent with different types of environment.
- Actuators: It specifies the way the agent affects the environment by taking expected actions.
- Sensors: It specifies the way the agent gets information from its environment.
These terms acronymically called as PEAS (Performance measure, Environment, Actuators, Sensors). To understand PEAS terminology in more detail, let’s discuss each element in the following example:
| Agent Type | Performance | Environment | Actuators | Sensors |
| Taxi Driver | Safe, fast, correct destination | Roads, traffic | Steering, horn, breaks | Cameras, GPS, speedometer |
Properties/Classification of Task Environment
Fully Observable vs. Partially Observable:
When an agent’s sensors allow access to complete state of the environment at each point of time, then the task environment is fully observable, whereas, if the agent does not have complete and relevant information of the environment, then the task environment is partially observable.
Example: In the Checker Game, the agent observes the environment completely while in Poker Game, the agent partially observes the environment because it cannot see the cards of the other agent.
Note: Fully Observable task environments are convenient as there is no need to maintain the internal state to keep track of the world.
Single-agent vs. Multiagent
When a single agent works to achieve a goal, it is known as Single-agent, whereas when two or more agents work together to achieve a goal, they are known as Multiagents.
Example: Playing a crossword puzzle – single agent
Playing chess –multiagent (requires two agents)
Deterministic vs. Stochastic
If the agent’s current state and action completely determine the next state of the environment, then the environment is deterministic whereas if the next state cannot be determined from the current state and action, then the environment is Stochastic.
Example: Image analysis – Deterministic
Taxi driving – Stochastic (cannot determine the traffic behavior)
Note: If the environment is partially observable, it may appear as Stochastic
Episodic vs. Sequential
If the agent’s episodes are divided into atomic episodes and the next episode does not depend on the previous state actions, then the environment is episodic, whereas, if current actions may affect the future decision, such environment is sequential.
Example: Part-picking robot – Episodic
Chess playing – Sequential
Static vs. Dynamic
If the environment changes with time, such an environment is dynamic; otherwise, the environment is static.
Example: Crosswords Puzzles have a static environment while the Physical world has a dynamic environment.
Discrete vs. Continuous
If an agent has the finite number of actions and states, then the environment is discrete otherwise continuous.
Example: In Checkers game, there is a finite number of moves – Discrete
A truck can have infinite moves while reaching its destination – Continuous.
Known vs. Unknown
In a known environment, the agents know the outcomes of its actions, but in an unknown environment, the agent needs to learn from the environment in order to make good decisions.
Example: A tennis player knows the rules and outcomes of its actions while a player needs to learn the rules of a new video game.
Note: A known environment is partially observable, but an unknown environment is fully observable.
Structure of agents
The goal of artificial intelligence is to design an agent program which implements an agent function i.e., mapping from percepts into actions. A program requires some computer devices with physical sensors and actuators for execution, which is known as architecture.
Therefore, an agent is the combination of the architecture and the program i.e.
agent = architecture + program
Note: The difference between the agent program and agent function is that an agent program takes the current percept as input, whereas an agent function takes the entire percept history.
Types of Agent Programs
Varying in the level of intelligence and complexity of the task, the following four types of agents are there:
- Simple reflex agents: It is the simplest agent which acts according to the current percept only, pays no attention to the rest of the percept history. The agent function of this type relies on the condition-action rule – “If condition, then action.” It makes correct decisions only if the environment is fully observable. These agents cannot ignore infinite loop when the environment is partially observable but can escape from infinite loops if the agents randomize its actions.
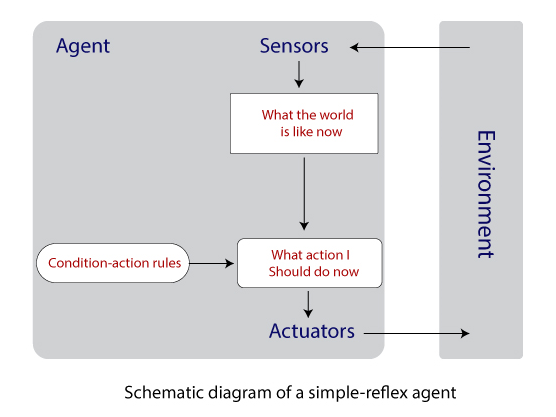
Example: iDraw, a drawing robot which converts the typed characters into
writing without storing the past data.
Note: Simple reflex agents do not maintain the internal state and do not depend on the percept theory.
- Model-based agent: These type of agents can handle partially observable environments by maintaining some internal states. The internal state depends on the percept history, which reflects at least some of the unobserved aspects of the current state. Therefore, as time passes, the internal state needs to be updated which requires two types of knowledge or information to be encoded in an agent program i.e., the evolution of the world on its own and the effects of the agent’s actions.
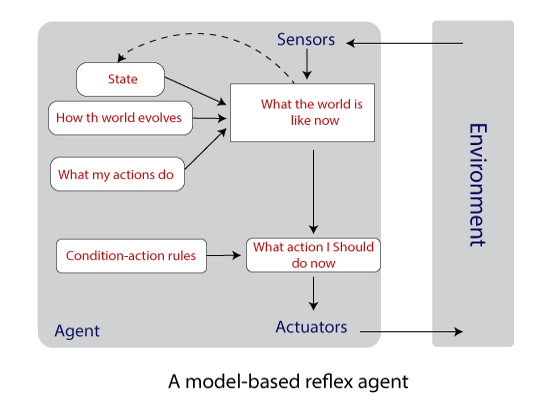
Example: When a person walks in a lane, he maps the pathway in his mind.
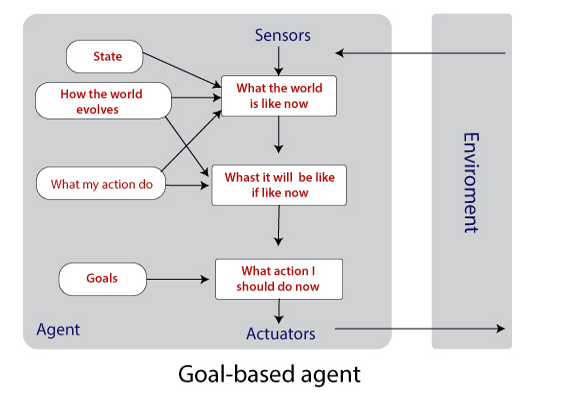
- Goal-based agents: It is not sufficient to have the current state information unless the goal is not decided. Therefore, a goal-based agent selects a way among multiple possibilities that helps it to reach its goal.
Note: With the help of searching and planning (subfields of AI), it becomes easy for the Goal-based agent to reach its destination.
- Utility-based agents: These types of agents are concerned about the performance measure. The agent selects those actions which maximize the performance measure and devote towards the goal.
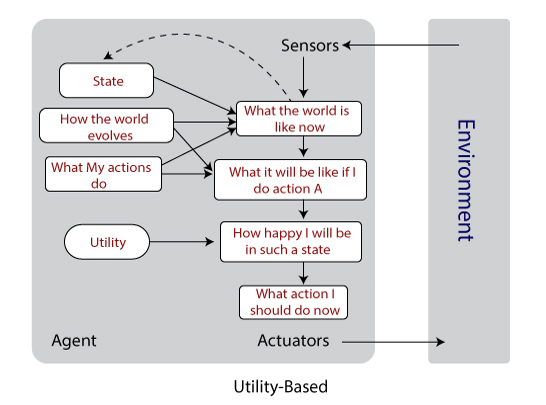
Example: The main goal of chess playing is to ‘check-and-mate’ the king, but the player completes several small goals previously.
Note: Utility-based agents keep track of its environment, and before reaching its main goal, it completes several tiny goals that may come in between the path.
- Learning agents: The main task of these agents is to teach the agent machines to operate in an unknown environment and gain as much knowledge as they can. A learning agent is divided into four conceptual components:
- Learning element: This element is responsible for making improvements.
- Performance element: It is responsible for selecting external actions according to the percepts it takes.
- Critic: It provides feedback to the learning agent about how well the agent is doing, which could maximize the performance measure in the future.
- Problem Generator: It suggests actions which could lead to new and informative experiences.
Example: Humans learn to speak only after taking birth.
Note: The objective of a Learning agent is to improve the overall performance of the agent.
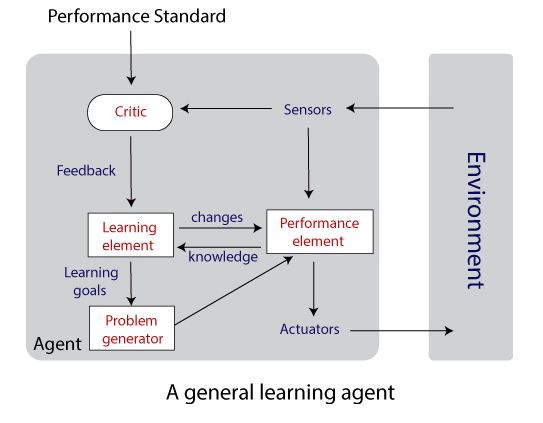
Working of an agent program’s components
The function of agent components is to answer some basic questions like “What is the world like now?”, “what do my actions do?” etc.
We can represent the environment inherited by the agent in various ways by distinguishing on an axis of increasing expressive power and complexity as discussed below:
- Atomic Representation: Here, we cannot divide each state of the world. So, it does not have any internal structure. Search, and game-playing, Hidden Markov Models, and Markov decision process all work with the atomic representation.
- Factored Representation: Here, each state is split into a fixed set of attributes or variables having a value. It allows us to represent uncertainty. Constraint satisfaction, propositional logic, Bayesian networks, and machine learning algorithms work with the Factored representation.
Note: Two different factored states can share some variables like current GPS location, but two different atomic states cannot do so.
- Structured Representation: Here, we can explicitly describe various and varying relationships between different objects which exist in the world. Relational databases and first-order logic, first-order probability models, natural language understanding underlie structured representation.