
Inference in First-order Logic
While defining inference, we mean to define effective procedures for answering questions in FOPL.
FOPL offers the following inference rules:
- Inference rules for quantifiers
- Universal Instantiation (UI): In this, we can infer any sentence by substituting a ground term (a term without variables) for the variables. In short, when we create the FOPL of the given statement, we can easily infer any other statement using that FOPL
Notation: Let, SUBST( θ , α ) be the result of the given sentence α , and its substitute is θ.

where v is the variable and g is the ground term.
For example: Every man is mortal.
It is represented as ∀ x: man(x) → mortal(x).
In UI, we can infer different sentences as:
man(John) → mortal(John)
man(Aakash) → mortal(Aakash), etc.
- Existential Instantiation(EI): In EI, the variable is substituted by a single new constant symbol.
Notation: Let, the variable be v which is replaced by a constant symbol k for any sentence α The value of k is unique as it does not appear for any other sentence in the knowledge base. Such type of constant symbols are known as Skolem constant. As a result, EI is a special case of Skolemization process.
Note: UI can be applied several times to produce many sentences, whereas EI can be applied once, and then the existentially quantified sentences can be discarded.
For example: ∃x:steal(x, Money).
We can infer from this: steal(Thief, Money)
- Generalized Modus Ponen: It is a lifted version of Modus Ponen as it uplifts the Modus Ponens from ground propositions to FOPL. Generalized Modus Ponen is more generalized than Modus Ponen. It is because, in generailzed, the known facts and the premise of the implication are matched only upto a substitution, instead of its exact match.
Notation: For atomic sentences like pi.pi’ and q where we have a substitute
θ that SUBST( θ, pi) for each i.
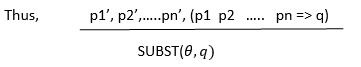
For example: p1’ is Thief(Charlie) p1 is Thief(x)
p2’ is Silent(y) p2 is Silent(y)
θ will be {x/Charlie, y/Charlie} q is evil(x)
SUBST(θ,q ) is evil(Charlie).
- Unification: It is the key component of First-order inference algorithms. Unification is the process used by the lifted inference rules to find substituents that could give identical but different logical expressions. It means the meaning of the sentence should not be changed, but it should be expressed in multiple ways. The UNIFY algorithm in unification takes two sentences as input and then returns a unifier if one exists:
UNIFY(p,q)= θ where SUBST( θ , p) = SUBST( θ, q).
Let see how UNIFY works with the help of the below example:
Given: Knows(Ram,x). The question is- Whom does Ram knows?
The UNIFY algorithm will search all the related sentences in the knowledge base, which could unify with Knows(Ram,x).
UNIFY (Knows(Ram, x), Knows(Ram, Shyam))≡{x/Shyam}
UNIFY (Knows{Ram,x}, Knows{y, Aakash})≡{x/Aakash, y/Ram}
UNIFY (Knows{Ram,x}, Knows{x, Raman})≡fails.
The last one failed because we have used the same variable for two persons at the same time.
Unification Algorithm
Earlier, we have studied TELL and ASK functions which are used to inform and interrogate a knowledge base. These are the primitive functions of STORE and FETCH functions. STORE function is used to store a sentence s into the knowledge base and FETCH function is used to return all the unifiers with some sentences.
function UNIFY(a , b, θ) returns a substitution to make a, b identical
inputs: a , a variable, constant, list, or compound expression
a, a variable, constant, list, or compound expression
θ, the substitution built up earlier (optional, defaults to empty)
if θ = failure then return failure
else if a = b then return θ
else if VARIABLE?(a ) then return UNIFY-VAR(a , b, θ)
else if VARIABLE?(b) then return UNIFY-VAR(a, b, θ)
else if COMPOUND?(a ) and COMPOUND?(b) then
return UNIFY(a.ARGS, b.ARGS, UNIFY(a.OP, b.OP, θ))
else if LIST?(a) and LIST?(b) then
return UNIFY(a .REST, b.REST, UNIFY(a .FIRST, b.FIRST, θ))
else return failure
function UNIFY-VAR(var, a , θ) returns a substitution
if {var/val} ∈ θthen return UNIFY(val , a , θ)
else if {a/val} ∈ θ then return UNIFY(var, val , θ)
else if OCCUR-CHECK?(var, a ) then return failure
else return add {var/a } to θ
Note: In the above example: Knows(Ram, x) → It is an instance of FETCH function.
- Forward Chaining: In forward chaining, we start with the atomic sentences in the knowledge base and apply Modus Ponen in forward direction. Also adding new sentences until any inference is not made.
Note: We will understand Forward Chaining in detail in Forward Chaining section.
- Backward Chaining:This algorithm is opposite of forward chaining algorithm. It works in backward direction. It starts from the goal, chain through the rules to search the known facts and infer sentences from the given facts in backward direction.
Note: We will understand Backward Chaining in detail in Backward Chaining section.
- Resolution Method: Unification, Backward Chaining as well as Forward Chaining, all are based on the resolution method. The resolution method is a decision-making rule where a machine decides what to do and what not to do. It can be understood as:
Firstly, we convert the given statement into FOPL.
Secondly, we infer some related sentences from it.
Then, realizing our goal, we need to prove it.
Here, we make use of the resolution method to decide the best possible FOPL from various.
Note: We will understand resolution method for both Propositional logic and Predicate logic in our next section.